
Have you ever tried to make code run faster only for it to slow down instead?
The project I was working on had a piece of code that pulled data from a data source, iterated over it, and processed each entry. Pretty straight-forward.
The existing code was fine, but a colleague noted that the algorithm was a bit inefficient and could be faster. The reason being that the algorithm scaled very poorly as the size of the input data increased. In more technical terms, they said the Big O complexity of the algorithm was O(n²) and could be improved to O(n).
I looked over the code and they were right. The algorithm could be refactored to have linear complexity. I was excited, I love speeding up code! The code already ran faster than any human could perceive it, but I figured it’s worth squeezing every little bit of performance out of our code. Every little bit helps.
The refactor required a couple of changes to other functions, but overall it was simple to do. Once I was done everything still worked as it should and all the tests passed. Success.
I wanted to show off the speed of the new code for the code review, so I timed it. I measured the execution time of the new code, saved the results, then rolled back all my changes, and ran the same test again with the old code.
The only problem was that the new code was ten times slower than the old code!

I spent some time digging into what was going on. Eventually I found two reasons for the poor performance.
- While the old code queried the data-source 7 times, the new code required querying it four times as often. A total of 28 times. If that wasn’t bad enough, the new queries were also more complex and took longer to execute.
- The new code was faster at iterating over the data, but required an extra step to put the data in a different structure.

So how did this account for such a big performance difference?
First off, in this particular system, running a query on the data-source is slow. Very slow. So making four times more queries has a huge impact.
Secondly, the old algorithm was able to be a bit more efficient while processing the data and didn’t need that extra step. I didn’t even think twice about adding that step because it was so small. The execution time for each element was almost too fast to measure at around 0.048 ms, but since it had to run over every single element, that time quickly added up.
In summary, the cost of the extra queries and the new setup cost completely over-shadowed the benefit of the faster algorithm.
Of course this issue only shows up because the data-set is so small. If we increase the data-set size toward infinity, the new algorithm will run faster, right?
Yes. The old algorithm has a complexity of O(n²) vs. a complexity of O(n) for the new algorithm. Or maybe something like O(n) + y (where y is the extra setup cost). So there will always come a point where n² > n + y.
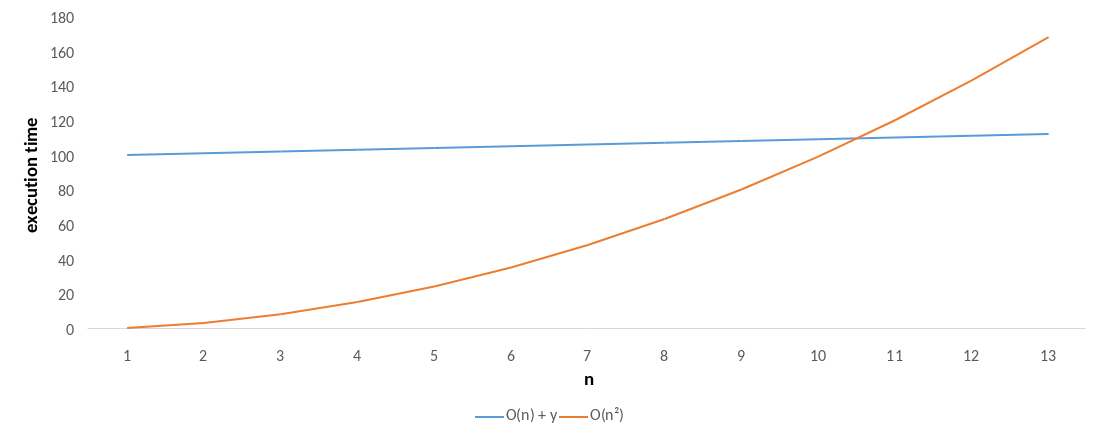
The graph above shows this. The orange line represents the old algorithm and the blue line represents the new algorithm. While the blue line starts out with a higher execution time, as the size of the input increases, the execution time of the orange line increases at a much faster rate. Eventually overtaking the blue line.
So why am I even writing about this? The new algorithm is better at handling larger data, so we should just use that. The key question is “will that ever happen?”
In this case, the answer is no. Based on what this data represents, what it is used for, and where it comes from, I know for a fact that the size of the input data will never tend toward infinity. It will never even double its current size.
That makes the original algorithm better for this use-case. It is much faster in every scenario that matters.
So what did I learn from all this? A few things.
- When you are trying to improve performance, always, always, always benchmark your code before and after you change it.
- Code doesn’t exist in isolation. Make sure you investigate what other impacts the refactor you are doing will have. Some are more expensive than you might think.
- Know your domain. Don’t optimize code for use-cases that will never happen.
- Last but not least, don’t waste time fixing something that isn’t broken. The old code was already faster than it needed to be. I could have better used my time by building something that delivered actual value.
Also on Medium
Hector Smith